Наверное, одним из первых вопросов, возникающих у начинающих программистов на T-SQL, это вопрос "А как получить выборку из таблицы, имя которой занесено в переменную?"
Т.к. в T-SQL нет возможности использовать в некоторых частях запроса значения переменных, то единственным доступным решением является использование динамического запроса. Идея очень проста: в специально определнной переменной "собирается" строка запроса, которая должна выполняться. Далее эта строка запускается на выполнение. Запуск можно осуществить двумя способами
- с помощью команды EXECUTE
- с помощью системной процедуры sp_executesql.
Выглядит это приблизительно так
I.Особенности динамического запроса
1. Динамический запрос ВСЕГДА выполняется В ТОМ-ЖЕ КОННЕКТЕ и КАК ОТДЕЛЬНЫЙ ПАКЕТ(batch). Другими словами при использовании такого запроса,
- вы ни имеете доступа к локальным переменным, объявленым до вызова динамического запроса (однако возможен доступ к cозданным ранее временным таблицам)
- локальные временые таблицы и переменные, созданные во время выполнения команды exec, будут недоступны в вызывающей процедуре, т.к. будут удалены по окончании пакета, в котором выполняется exec.
2. Динамический запрос ВСЕГДА выполняется с ПРАВАМИ ПОЛЬЗОВАТЕЛЯ, ВЫЗВАВШЕГО ПРОЦЕДУРУ, а не с правами владельца процедуры. Другими словами, если владельцем процедуры Procedure1 является User1, который имеет права к таблице Table1, то для пользователя User2 мало назначить права на выполнение процедуры Procedure1, если обращение в ней к таблице Table1 идет через динамический запрос. Придется давать ему соответствующие права и непосредственно для Table1.
3. Компиляция запроса происходят непосредственно перед его вызовом. Т.е. обо всех синтаксических ошибках вы узнаете только в этот момент.
II.Особенности использования команда exec
1. Команда exec поддерживает к качестве аргумента конкатенацю строк и/или переменных. НО не поддерживатеся конкатенация результатов выполнения функций, т.е. конструкции вида
exec
("SELECT * FROM "
+ LEFT
(@TableName, 10
))
запрещены к использованию.
2. В команде нет входных/выходных параметров.
III.Особенности использования процедуры sp_executesql
1. Процедура НЕ поддерживает в качестве параметров конкатенацию строк и/или переменных.
2. Текст запроса должен быть либо переменной типа NVARCHAR/NCHAR, либо такого же типа стринговой константой.
3. Имеется возможность передачи параметров в выполняемый скрипт и получение выходных значений
Последнее явно в документации не описано, поэтому вот несколько примеров
В данном примере в динамический запрос передаются 4 переменные, три из которых являюся выходными
declare @var1 int , @var2 varchar (100 ), @var3 varchar (100 ), @var4 int declare @mysql nvarchar (4000 ) set @mysql = "set @var1 = @var1 + @var4; set @var2 = " "CCCC" "; set @var3 = @var3 + " "dddd" "" set @var1 = 0 set @var2 = "BBBB" set @var3 = "AAAA" set @var4 = 10 select @var1, @var2, @var3 exec sp_executesql @mysql, N"@var1 int out, @var2 varchar(100) out, @var3 varchar(100) out, @var4 int" , @var1 = @var1 out , @var2 = @var2 out , @var3 = @var3 out , @var4 = @var4 select @var1, @var2, @var3
В данном примере в динамическом запросе открывается курсор, который доступен в вызывающей процедуре через выходную переменную
USE pubs declare @cur cursor exec sp_executesql N"set @curvar= cursor local for select top 10 au_id, au_lname, au_fname from authors open @curvar" , N"@curvar cursor output " , @curvar=@cur output FETCH NEXT FROM @cur WHILE @@FETCH_STATUS = 0 BEGIN FETCH NEXT FROM @cur END
Резюме(более IMHO, чем обязательные требования)
Динамический запрос очень полезная и иногда просто незаменимая вещь, НО способы его реализации и конкретно через вызов в отдельном пакете с правами пользователя, вызвавшего процедуру, принижают его практическое МАССОВОЕ применение.
В Microsoft SQL Server есть особый тип данных TABLE, на основе которого мы можем создавать табличные переменные , для того чтобы использовать их в своих инструкциях и процедурах, и сегодня мы с Вами рассмотрим эти переменные, узнаем, как они объявляются и какие у этих переменных особенности.
Описание табличных переменных MS SQL Server
Табличные переменные – это переменные с особым типом данных TABLE, которые используются для временного хранения результирующего набора данных в виде строк таблицы. Появились они еще в 2005 версии SQL сервера. Использовать такие переменные можно и в хранимых процедурах, и в функциях, и в триггерах, и в обычных SQL пакетах. Создаются табличные переменные так же, как и обычные переменные, путем их объявления инструкцией DECLARE.
Переменные такого типа предназначены в качестве альтернативы временным таблицам. Если говорить о том, что лучше использовать табличные переменные или временные таблицы, то однозначного ответа нет, у табличных переменных есть и плюсы, и минусы. Например, лично мне нравиться использовать табличные переменные, потому что их удобно создавать (т.е. объявлять ) и не нужно думать об их удалении или очищение в конце инструкции, так как они автоматически очищаются (как и обычные переменные ). Но при этом табличные переменные лучше использовать только тогда, когда Вы собираетесь хранить в них небольшой объём данных, в противном случае рекомендуется использовать временные таблицы.
Преимущества табличных переменных в Microsoft SQL Server
- Табличные переменные ведут себя как локальные переменные. Они имеют точно определенную область применения;
- Табличные переменные автоматически очищаются в конце инструкции, где они были определены;
- При использовании табличных переменных в хранимых процедурах повторные компиляции происходят реже, чем при использовании временных таблиц;
- Транзакции с использованием переменных TABLE продолжаются только во время процесса обновления соответствующей переменной. За счет этого табличные переменные реже подвергаются блокировке и требуют меньше ресурсов для ведения журналов регистрации.
Недостатки табличных переменных в MS SQL Server
- Запросы, которые изменяют переменные TABLE, не создают параллельных планов выполнения запроса;
- Переменные TABLE не имеют статистики распределения и не запускают повторных компиляций, поэтому рекомендуется использовать их для небольшого количества строк;
- Табличные переменные нельзя изменить после их создания;
- Табличные переменные нельзя создавать путем инструкции SELECT INTO;
- Переменные TABLE не изменяются в случае откатов транзакций, так как имеют ограниченную область действия и не являются частью постоянных баз данных.
Примеры использования табличных переменных в Microsoft SQL Server
Сейчас давайте перейдем к практике, и для начала хотелось бы отметить, что в качестве сервера у меня выступает Microsoft SQL Server 2016 Express , другими словами все запросы ниже запускались на данной версии СУБД.
Сначала давайте создадим тестовую таблицу и заполним ее тестовыми данными, для того чтобы посмотреть, как можно использовать табличные переменные вместе с обычными таблицами.
CREATE TABLE TestTable(ProductId INT IDENTITY(1,1) NOT NULL, ProductName VARCHAR(50) NULL CONSTRAINT PK_TestTable PRIMARY KEY CLUSTERED (ProductId ASC)) GO INSERT INTO TestTable (ProductName) VALUES ("Компьютер"), ("Монитор"), ("Принтер") GO SELECT * FROM TestTable

С помощью инструкции CREATE TABLE я создал таблицу TestTable, затем для добавления данных в таблицу я использовал инструкцию INSERT совместно с конструктором табличных значений VALUES , затем с помощью SELECT сделал выборку из только что созданной таблицы.
Объявление табличной переменной и ее использование
В данном примере мы объявим табличную переменную, добавим в нее данных, и сделаем выборку из двух таблиц (табличной переменной и обычной таблицы ) с объединением.
Объявление табличной переменной DECLARE @TableVar TABLE(ProductId INT NOT NULL, Price MONEY NULL); --Добавление данных в табличную переменную INSERT INTO @TableVar (ProductId, Price) VALUES (1, 500), (2, 300), (3, 200) --Использование табличной переменной с объединением данных SELECT TTable.ProductId, TTable.ProductName, TVar.Price FROM @TableVar TVar LEFT JOIN TestTable TTable ON TVar.ProductId = TTable.ProductId

Создание табличной переменной с первичным ключом, ограничением UNIQUE и с некластеризованным индексом
В данном примере показано, как можно создавать первичный ключ, ограничения UNIQUE и некластеризованные индексы для табличных переменных. Возможность создания некластеризованного индекса появилась, начиная с версии Microsoft SQL Server 2014.
Объявление табличной переменной DECLARE @TableVar TABLE(ProductId INT NOT NULL PRIMARY KEY, --Первичный ключ ProductName VARCHAR(50) NOT NULL, Price MONEY NOT NULL, UNIQUE (ProductName, Price), --Ограничение INDEX IX_TableVar NONCLUSTERED (Price) --Некластеризованный индекс); --Добавление данных в табличную переменную INSERT INTO @TableVar (ProductId, ProductName, Price) VALUES (1, "Компьютер", 500), (2, "Монитор", 300), (3, "Принтер", 200); --Выборка данных SELECT ProductName FROM @TableVar WHERE Price > 200

На этом мой рассказ о табличных переменных закончен, если Вы хотите детально изучить язык T-SQL, то рекомендую почитать мою книгу «Путь программиста T-SQL », надеюсь, материал был Вам полезен, пока!
Задание значений переменных
В настоящее время в языке SQL предусмотрены два способа задания значения переменной - для этой цели можно использовать оператор SELECT или SET. С точки зрения выполняемых функций эти операторы действуют почти одинаково, не считая того, что оператор SELECT позволяет получить исходное присваиваемое значение из таблицы, указанной в операторе SELECT.
Оператор SET обычно используется для задания значений переменных в такой форме, какая более часто встречается в процедурных языках. В качестве типичных примеров применения этого оператора можно указать следующие:
SET @b = @a * 1.5
Обратите внимание на то, что во всех этих операторах непосредственно осуществляются операции присваивания, в которых используются либо явно заданные значения, либо другие переменные. С помощью оператора SET невозможно присвоить переменной значение, полученное с помощью запроса; запрос должен быть выполнен отдельно и только после этого полученный результат может быть присвоен с помощью оператора SET. Например, попытка выполнения такого оператора вызывает ошибку:
SET @c = COUNT(*) FROM City
а следующий оператор выполняется вполне успешно:
SET @c = (SELECT COUNT(*) FROM City)
Оператор SELECT обычно используется для присваивания значений переменным, если источником информации, которая должна быть сохранена в переменной, является запрос. Например, действия, осуществляемые в приведенном выше коде, гораздо чаще реализуются с помощью оператора SELECT:
SELECT @c = COUNT(*) FROM City
Обратите внимание на то, что данный код немного понятнее (в частности, он более лаконичен, хотя и выполняет те же действия).
Таким образом, можно, сформулировать следующее общепринятое соглашение по использованию того и другого оператора.
Оператор SET используется, если должна быть выполнена простая операция присваивания значения переменной, т.е. если присваиваемое значение уже задано явно в форме определенного значения или в виде какой-то другой переменной.
Оператор SELECT применяется, если присваивание значения переменной должно быть основано на запросе.
Использование переменных в запросах SQL
Одним из полезных свойств языка T-SQL является то, что переменные могут использоваться в запросах без необходимости создания сложных динамических строк, встраивающих переменные в программный код. Динамический SQL продолжает свое существование, но одиночное значение можно изменить проще - с помощью переменной.
Везде, где в запросе может использоваться выражение, может использоваться и переменная. В следующем примере продемонстрировано использование переменной в предложении WHERE:
DECLARE @IdProd int;
SET @IdProd = 1;
SELECT
В этом материале мы с Вами рассмотрим основы программирования на языке T-SQL , узнаем, что это за язык, какими основными возможностями он обладает, какие конструкции включает и, конечно же, в процессе всего этого я буду приводить примеры кода.
И начать хотелось бы с того, что на этом сайте мы с Вами уже достаточно много материала посвятили языку SQL и в частности его расширению Transact-SQL (как Вы понимаете T-SQL это сокращение от Transact-SQL ). И даже составили небольшой справочник для начинающих по данному языку и, конечно же, рассмотрели множество примеров, но как таковое программирование на T-SQL там, например, переменные, условные конструкции, комментарии мы затрагивали, но не заостряли на этом внимания. Но так как у нас сайт для начинающих программистов я решил посвятить этот материал именно этим основам.
Язык программирования T-SQL
Transact-SQL (T-SQL ) – расширение языка SQL от компании Microsoft и используется в SQL Server для программирования баз данных.
SQL Server включает много конструкций, компонентов, функций которые расширяют возможности языка SQL стандарта ANSI, в том числе и классическое программирование, которое отличается от обычного написания запросов.
И сегодня мы с Вами рассмотрим ту часть основ языка T-SQL, которая подразумевает написание кода для реализации некого функционала (например, в процедуре или функции ), а не просто какого-то запроса к базе данных.
Переменные в T-SQL
И начнем мы с переменных, они нужны для того, чтобы хранить какие-то временные данные, которые нам необходимо на время сохранить, а затем использовать.
Существует две разновидности переменных в T-SQL — это локальные и глобальные. Локальные переменные существуют только в пределах сеанса, во время которого они были созданы, а глобальные используются для получения информации о SQL сервере или какой-то меняющейся информации в базе данных.
Локальные переменные объявляются с помощью ключевого слова DECLARE и начинаются со знака @ . Как и во многих языках программирования, переменные в T-SQL должны иметь свой тип данных. Типов данных в SQL сервере достаточно много мы их подробно рассмотрели в справочнике, который я упоминал чуть выше.
Для присвоения значения переменной можно использовать команды SET или Select .
Как я уже сказал, глобальные переменные нужны для того, чтобы получать какую-либо информацию о сервере или о базе данных, например, к глобальным переменным в SQL Server относятся:
- @@ROWCOUNT – хранит количество записей, обработанных предыдущей командой;
- @@ERROR – возвращает код ошибки для последней команды;
- @@SERVERNAME — имя локального SQL сервера;
- @@VERSION — номер версии SQL Server;
- @@IDENTITY — последнее значение счетчика, используемое в операции вставки (insert ).
Теперь для примера давайте создадим две переменной с типом данных INT, присвоим им значения, первой с помощью команды SET, а второй с помощью команды Select, затем просто выведем на экран эти значения, а также выведем и значение переменной @@VERSION, т.е. узнаем версию SQL сервера.
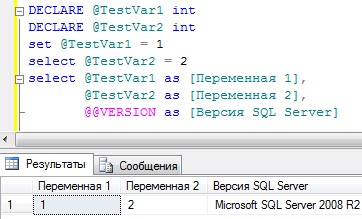
DECLARE @TestVar1 INT DECLARE @TestVar2 INT SET @TestVar1 = 1 SELECT @TestVar2 = 2 SELECT @TestVar1 AS [Переменная 1], @TestVar2 AS [Переменная 2], @@VERSION AS [Версия SQL Server]
Пакеты
Пакет в T-SQL — это команды или инструкции SQL, которые объединены в одну группу и при этом SQL сервер будет компилировать, и выполнять их как одно целое.
Для того чтобы дать понять SQL серверу, что Вы передаете пакет команд необходимо указывать ключевое слово GO после всех команд, которые Вы хотите объединить в пакет.
Локальные переменные будут видны только в пределах того пакета, в котором они были созданы, т.е. обратиться к переменной после завершения пакета Вы уже не сможете.
Допустим, если пример, который мы использовали выше, объединить в пакет, а потом попробовать получить значение переменных, то у нас получится следующее:

Т.е. мы видим, что у нас вышла ошибка, связанная с тем, что переменная @TestVar1 у нас не объявлена.
Условные конструкции
Эти конструкции подразумевают ветвление, т.е. в зависимости от выполнения или невыполнения определенных условий инструкции T-SQL будут менять свое направление.
IF…ELSE
Эта конструкция есть, наверное, во всех языках программирования она подразумевает проверку выполнения условий и если все проверки пройдены, то выполняется команда идущая следом, если нет, то не выполняется ничего, но можно указать ключевое слово ELSE и тогда в этом случае будут выполняться операторы указанные после этого слова.

DECLARE @TestVar1 INT DECLARE @TestVar2 VARCHAR(20) SET @TestVar1 = 5 IF @TestVar1 > 0 SET @TestVar2 = "Больше 0" ELSE SET @TestVar2 = "Меньше 0" SELECT @TestVar2 AS [Значение TestVar1]
IF EXISTS
Данная конструкция позволяет определить наличие записей определенных условием. Например, мы хотим знать есть ли в таблице те или иные записи и при обнаружении первого совпадения обработка команды прекращается. По сути это то же самое, что и COUNT(*) > 0.
К примеру, мы хотим проверить есть ли записи со значение id >=0 в таблице test_table, и на основе этого мы будем принимать решение, как действовать дальше
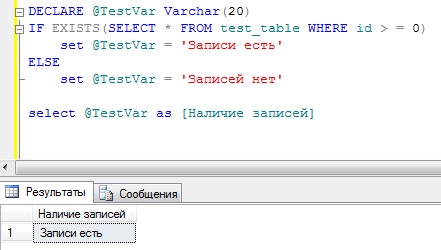
DECLARE @TestVar VARCHAR(20) IF EXISTS(SELECT * FROM test_table WHERE id > = 0) SET @TestVar = "Записи есть" ELSE SET @TestVar = "Записей нет" SELECT @TestVar AS [Наличие записей]
CASE
Данная конструкция используется совместно с оператором select и предназначена она для замены многократного использования конструкции IF. Она полезна в тех случаях, когда необходимо проверять переменную (или поле ) на наличие определенных значений.

DECLARE @TestVar1 INT DECLARE @TestVar2 VARCHAR(20) SET @TestVar1 = 1 SELECT @TestVar2 = CASE @TestVar1 WHEN 1 THEN "Один" WHEN 2 THEN "Два" ELSE "Неизвестное" END SELECT @TestVar2 AS [Число]
BEGIN…END
Эта конструкция необходима для создания блока команд, т.е. например, если бы мы хотели выполнить не одну команду после блока IF, а несколько, то нам бы пришлось писать все команды внутри блока BEGIN…END.
Давайте модифицируем наш предыдущий пример (про IF EXISTS ) так, чтобы при наличии записей id > = 0 в таблице test_table, мы помимо присвоения значения переменной @TestVar, выполним еще и update, т.е. обновление неких данных в этой же таблице, а также выведем количество строк, которые мы обновили, используя глобальную переменную @@ROWCOUNT.
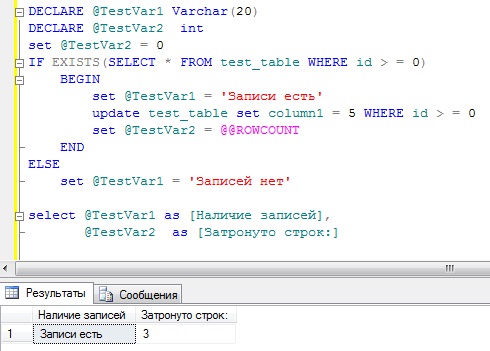
DECLARE @TestVar1 VARCHAR(20) DECLARE @TestVar2 INT SET @TestVar2 = 0 IF EXISTS(SELECT * FROM test_table WHERE id > = 0) BEGIN SET @TestVar1 = "Записи есть" UPDATE test_table SET column1 = 5 WHERE id > = 0 SET @TestVar2 = @@ROWCOUNT END ELSE SET @TestVar1 = "Записей нет" SELECT @TestVar1 AS [Наличие записей], @TestVar2 AS [Затронуто строк:]
Циклы T-SQL
Если говорить в общем о циклах, то они нужны для многократного повторения выполнения команд. В языке T-SQL есть один цикл WHILE с предусловием , это означает, что команды начнутся, и будут повторяться до тех пор, пока выполняется условие перед началом цикла, также выполнение цикла можно контролировать с помощью ключевых слов BREAK и CONTINUE .
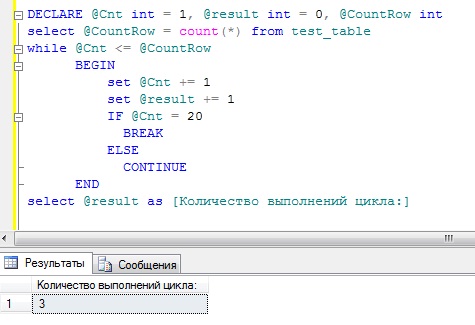
DECLARE @Cnt INT = 1, @result INT = 0, @CountRow INT SELECT @CountRow = COUNT(*) FROM test_table WHILE @Cnt <= @CountRow BEGIN SET @Cnt += 1 SET @result += 1 IF @Cnt = 20 BREAK ELSE CONTINUE END SELECT @result AS [Количество выполнений цикла:]
В данном примере мы сначала, конечно же, объявляем переменные (Cnt и result мы сразу инициализируем, таким способом можно задавать значения переменных, начиная с SQL Server 2008 ). Затем узнаем, сколько строк в таблице test_table и после этого проверяем, если количество строк в таблице больше или равно нашему счетчику, то входим в наш тестовый цикл. В цикле мы увеличиваем значение счетчика, записываем результат и снова проверяем, если наш счетчик достиг уже значения 20, то мы его принудительно завершим, если нет, то пусть работает дальше, до того как значение счетчика станет больше или равно количеству строк в таблице или до 20, если в таблице строк больше.
Комментарии
Они нужны для того, чтобы пояснять, делать заметки в коде, так как если код большой и сложный, то через некоторое время Вы можете просто забыть, почему именно так и для чего Вы написали тот или иной участок кода. В языке T-SQL бывают однострочные (—Текст) и многострочные комментарии (/*Текст*/).

Команды T-SQL
GOTO
С помощью этой команды можно перемещаться по коду к указанной метке. Например, ее можно использовать тогда когда Вы хотите сделать своего рода цикл, но без while.

DECLARE @Cnt INT = 0 Metka: --Устанавливаем метку SET @Cnt += 1 --Прибавляем к переменной 1 if @Cnt < 10 GOTO Metka --Если значение меньше 10, то переходим к метке SELECT @Cnt AS [Значение Cnt =]
WAITFOR
Команда может приостановить выполнение кода на время или до наступления заданного времени. Параметр DELAY делает паузу заданной длины, а TIME приостанавливает процесс до указанного времени. Значение параметров задается в формате hh:mi:ss

RETURN
Данная команда служит для безусловного выхода из запроса или процедуры. RETURN может использоваться в любой точке для выхода из процедуры, пакета или блока инструкций. Все что идет после этой команды не выполняется.

DECLARE @Cnt INT = 1, @result varchar(15) /*Если значение Cnt меньше 0, то следующие команды не выполнятся, и Вы не увидите колонку [Результат:]*/ IF @Cnt < 0 RETURN SET @result = "Cnt больше 0" SELECT @result AS [Результат:]
Для передачи служебного сообщения можно использовать команду PRINT . В Management Studio это сообщение отобразится на вкладке «Сообщения» (Messages ).
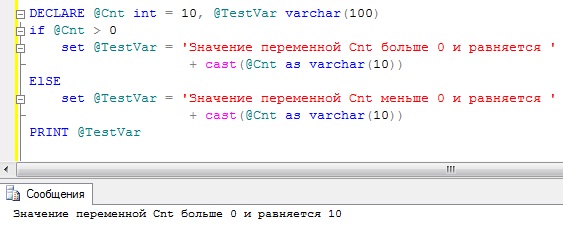
DECLARE @Cnt INT = 10, @TestVar varchar(100) IF @Cnt > 0 SET @TestVar = "Значение переменной Cnt больше 0 и равняется " + CAST(@Cnt AS VARCHAR(10)) ElSE SET @TestVar = "Значение переменной Cnt меньше 0 и равняется " + CAST(@Cnt AS VARCHAR(10)) PRINT @TestVar
Транзакции
Транзакция – это команда или блок команд, которые успешно завершаются или отменяются как единое целое. Другими словами, если одна команда или инструкция внутри транзакции завершилась с ошибкой, то все что было отработано перед ней, также отменяется, даже если предыдущие команды завершились успешно.
Этот механизм необходим для того, чтобы обеспечить целостность данных, т.е. допустим, у Вас есть процедура, которая перечисляет деньги с одного счета на другой, но может возникнуть ситуация при которой деньги снялись со счета, но не поступили на другой счет. К примеру, SQL инструкция, которая осуществляет снятие денег, отработала, а при выполнении инструкции, которая зачисляет деньги, возникла ошибка, другими словами, деньги снялись и просто потерялись. Чтобы этого не допускать, все SQL инструкции пишут внутри транзакции и тогда если наступит такая ситуация все изменения будут отменены, т.е. деньги вернутся на счет обратно.

Узнаем что у нас в таблице (id = IDENTITY) SELECT * FROM test_table --Начинаем транзакцию BEGIN TRAN --Сначала обновим все данные UPDATE test_table SET column1 = column1 - 5 --Затем просто добавим строки с новыми значениями INSERT INTO test_table SELECT column1 FROM test_table --Если ошибка, то все отменяем IF @@error != 0 BEGIN ROLLBACK TRAN RETURN END COMMIT TRAN --Смотрим что получилось SELECT * FROM test_table
В этом примере, если бы у нас в момент добавления данных (INSERT) возникла ошибка, то UPDATE бы отменился.
Обработка ошибок — конструкция TRY…CATCH
В процессе выполнения T-SQL кода может возникнуть непредвиденная ситуация, т.е. ошибка, которую необходимо обработать. В SQL сервере, начиная с SQL Server 2005, существует такая конструкция как TRY…CATCH , которая может отследить ошибку.

BEGIN TRY DECLARE @TestVar1 INT = 10, @TestVar2 INT = 0, @result INT SET @result = @TestVar1 / @TestVar2 END TRY BEGIN CATCH SELECT ERROR_NUMBER() AS [Номер ошибки], ERROR_MESSAGE() AS [Описание ошибки] END CATCH
В этом примере возникла ситуация что происходит деление на ноль (как Вы знаете делить на 0 нельзя ) и так как наш блок кода был помещен в конструкцию TRY у нас возникло исключение, при котором мы просто получаем номер ошибки и ее описание.
Я думаю для основ этого достаточно, если Вы хотите более подробно изучить все конструкции языка T-SQL, то рекомендую прочитать мою книгу «Путь программиста T-SQL », в которой уже более подробно рассмотрен язык T-SQL, у меня все, удачи!
Я хочу использовать одно и то же значение для разных запросов из разных БД
DECLARE @GLOBAL_VAR_1 INT = Value_1 DECLARE @GLOBAL_VAR_2 INT = Value_2 USE "DB_1" GO SELECT * FROM "TABLE" WHERE "COL_!" = @GLOBAL_VAR_1 AND "COL_2" = @GLOBAL_VAR_2 USE "DB_2" GO SELECT * FROM "TABLE" WHERE "COL_!" = @GLOBAL_VAR_2
но это дает ошибку.
Необходимо объявить скалярную переменную "@ GLOBAL_VAR_2".
Кто-нибудь может предложить какой-либо способ сделать это...?
11 ответов
Невозможно объявить глобальную переменную в Transact-SQL. Однако, если все, что вы хотите, чтобы ваши переменные были доступны для пакетов одного скрипта, вы можете использовать инструмент SQLCMD или режим SQLCMD SSMS и определить этот инструмент /переменные, зависящие от режима, например:
:setvar myvar 10
А затем используйте их следующим образом:
$(myvar)
Чтобы использовать режим SSQ SQLCMD:
Вы не можете объявить глобальные переменные в SQLServer.
Если вы используете Management Studio, вы можете использовать режим SQLCMD, как указано @Lanorkin.
В противном случае вы можете использовать CONTEXT_INFO для хранения одной переменной, которая видна во время сеанса и соединения, но после этого она исчезнет.
Только по-настоящему глобальным будет создать глобальную временную таблицу (с именем ## yourTableName) и сохранить там свои переменные, но это также исчезнет, когда все соединения будут закрыты.
Вы можете попробовать глобальную таблицу:
Create table ##global_var (var1 int ,var2 int) USE "DB_1" GO SELECT * FROM "TABLE" WHERE "COL_!" = (select var1 from ##global_var) AND "COL_2" = @GLOBAL_VAR_2 USE "DB_2" GO SELECT * FROM "TABLE" WHERE "COL_!" = (select var2 from ##global_var)
В этом конкретном примере ошибка связана с GO после операторов использования. Операторы GO сбрасывают среду, поэтому пользовательских переменных не существует. Они должны быть объявлены снова. И ответ на вопрос о глобальных переменных - Нет, глобальных переменных не существует, по крайней мере версии сервера Sql, равные или до 2008 года. Я не могу гарантировать то же самое для более новых версий сервера SQL.
С уважением, HINI
Начиная с SQL Server 2016 , новый способ обмена информацией в сеансе представлен через SESSION_CONTEXT и sp_set_session_context .
Вы можете использовать их как альтернативу CONTEXT_INFO() , в которой сохраняется только двоичное значение, ограниченное 128 байтами. Кроме того, пользователь может переписать значение в любое время, и использовать его для проверки безопасности не очень хорошо.
Следующие проблемы решаются с помощью новых утилит. Вы можете хранить данные в более удобном для пользователя формате:
EXEC sp_set_session_context "language", "English"; SELECT SESSION_CONTEXT(N"language");
Кроме того, мы можем пометить его как read-only:
EXEC sp_set_session_context "user_id", 4, @read_only = 1;
Если вы попытаетесь изменить контекст сеанса read-only , вы получите что-то вроде этого:
Сообщение 15664, уровень 16, состояние 1, процедура sp_set_session_context, строка 10 Невозможно установить ключ "user_id" в контексте сеанса. Ключ был установлен как только для этой сессии.
Попробуйте использовать; вместо GO . У меня это работало на 2008 R2 версии
DECLARE @GLOBAL_VAR_1 INT = Value_1; DECLARE @GLOBAL_VAR_2 INT = Value_2; USE "DB_1"; SELECT * FROM "TABLE" WHERE "COL_!" = @GLOBAL_VAR_1 AND "COL_2" = @GLOBAL_VAR_2; USE "DB_2"; SELECT * FROM "TABLE" WHERE "COL_!" = @GLOBAL_VAR_2;
Подобный результат можно получить, создав скалярные функции, которые возвращают значения переменных. Конечно, вызовы функций могут быть дорогостоящими, если вы используете их в запросах, которые возвращают большое количество результатов, но если вы ограничиваете набор результатов, все должно быть в порядке. Здесь я использую базу данных, созданную только для хранения этих полустатических значений, но вы также можете создавать их для каждой базы данных. Как видите, здесь нет входных переменных, только функция с хорошо названным именем, которая возвращает статическое значение: если вы измените это значение в функции, оно мгновенно изменится везде, где она используется (при следующем вызове). >
USE GO CREATE FUNCTION dbo.global_GetStandardFonts () RETURNS NVARCHAR(255) AS BEGIN RETURN "font-family:"Calibri Light","sans-serif";" END GO -- Usage: SELECT "
..." -- Result: ...

